




-
무료대세는 'AI'...2차 랠리 임박
-
무료바닥권 주가 턴어라운드 임박 종목
-
무료5/27일 무료추천주
-
무료하반기부터 해외시장 본격 모멘텀 터지는 대박주는?
-
무료신약 흥행, 매출 급증! 주가 탄력은 덤!
-
무료관세 무풍지대에 있으면서 방산 관련 국산화를 시킨 재료가 2개나 있는 기업???? #웨이비스
-
무료주가 턴어라운드 가속 예상...추세적 주가 흐름 상승초입 국면
-
무료현대무벡스
-
무료[19.81%상승, 공략종료]AI산업에 필수적인 전력! 이재명후보에 에너지믹스 수소 관련주! #에스퓨얼셀
-
무료트럼프 장남에 해군성 장관까지 온다!! K-조선 부각! 방문하는 조선소에 필수 자제 납품하는 기업! #케이프
-
무료[8.96%상승, 공략종료]SK USIM 해킹 사태!! 양자내성암호 기반 eSIM 상용화 부각 #아이씨티케이
-
무료2차전지 시장 독보적 기술력 보유
-
무료인벤티지랩을 시작으로 비만치료제 모멘텀 시작~ 급등주는?
-
무료지원 정책 날개 달고 반등 가능성 농후
-
무료정부 28조 청년 일자리 정책 수혜 기대감 #플랜티넷

[이슈] 한국제약바이오협회 “국민 데이터 활용해 신약 개발...수익은 국민에 환원을"
- 3일 전 / 2025.06.11 14:38 /
-
- 조회수 2
- 댓글 0


“우리나라의 가장 큰 장점은 전 국민 단일 건강보험 체계를 갖추고 있고, 의료 데이터도 잘 정리돼 있다는 점입니다. 한국이 글로벌 신약 개발 경쟁력을 확보하려면, 이 의료·바이오 데이터를 통합적으로 관리하고 활용할 수 있는 역량이 필요합니다.”
11일 온라인으로 열린 한국제약바이오협회 정책 제안 설명회에서 김화종 K-MELLODY(연합학습 기반 신약개발 가속화 프로젝트) 사업단장은 이같이 강조했다.
협회의 정책 제안 핵심은 “국민이 참여하는 신약개발”이다. 세계 최초로 공공 의료 데이터와 임상 정보를 안전하게 활용할 수 있는 기술 기반 즉 연합학습(Federated Learning) 방식을 도입해, AI 기반 신약개발이 가능하도록 하는 방안을 제안한 것이다. 이를 통해 민간 기업은 혁신적 기술 개발과 수익 창출을 가능케 하고, 그 수익은 데이터 제공자인 국민과 공유하는 선순환 구조를 만들겠다는 것이 주요 골자다.
◆ 개인정보 안전 활용 위해 '연합학습' 도입..."목적에 필요한 데이터만 사용"
한국제약바이오협회는 신약 개발의 속도를 높이기 위해 국민의 건강 데이터를 활용하되, 개인정보 보호를 최우선으로 하는 기술적 해결책으로 ‘연합학습’ 방식을 제안했다.
김 단장은 “우리나라 제약 산업이 세계 시장에서 차지하는 비중은 1.8% 수준으로, 특히 신약 개발 분야는 미국, 스위스, 일본 등 소수 선진국이 주도하고 있다”며, “국민 건강 데이터라는 자산을 활용해 이 격차를 줄일 필요가 있다”고 강조했다.
문제는 민감한 개인정보의 안전한 활용 여부다. 이를 위해 협회는 기존 방식과는 다른 ‘연합학습’ 기술을 제안했다. 연합학습은 데이터를 중앙 서버로 모으지 않고, 각 기관의 내부에 데이터를 보관한 채 AI 모델의 파라미터(가중치)만 주고받아 공동으로 학습하는 방식이다.
김 단장은 “이 방식의 첫 번째 장점은 데이터가 밖으로 나가지 않는다는 점”이라며, “두 번째는 AI 모델을 먼저 만든 후, 그 모델이 필요한 데이터만 학습에 사용하는 ‘모델 퍼스트(Model-First)’ 전략을 따른다는 것”이라고 설명했다.
이어 “그동안은 ‘일단 데이터를 줘보라’는 식의 ‘데이터 퍼스트(Data-First)’ 접근이 일반적이었지만, 이는 목적이 불분명해 국민 데이터의 활용에 제약이 컸다”며, “이제는 모델 중심 접근을 통해 목적이 명확한 데이터 활용 체계를 만들 수 있다”고 말했다.
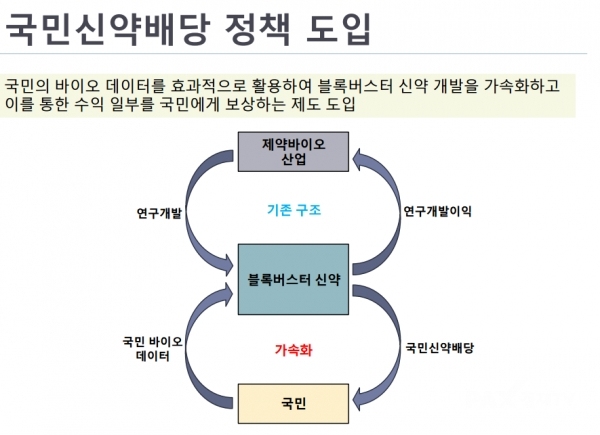
◆ “국민이 제공한 데이터 활용, 발생하는 수익은 국민에게 돌아가야”
협회는 이번 정책 제안의 핵심을 “국민 참여형 신약 개발 구조”라고 규정했다. 국민의 건강·바이오 데이터를 활용해 신약을 개발하고, 이를 통해 발생한 수익은 다시 국민에게 환원하는 공공성과 경제성이 결합된 선순환 모델을 제시한 것이다.
김 단장은 “정밀 바이오 데이터, 임상 데이터, 공공 데이터 등은 결국 국민으로부터 나온 것”이라며, “국민이 참여하는 신약 개발 체계를 구축하고, 그 수익 역시 국민에게 돌아갈 수 있어야 한다”고 강조했다.
이러한 구조를 실현하기 위해서는 기술적 신뢰성 확보는 물론, 이를 뒷받침할 명확한 법적·제도적 기반이 필수적이라는 입장이다.
김 단장은 “결국 누군가는 수익을 내야 국가에도 경제적 혜택이 돌아온다”며, “블록버스터 신약을 개발하는 것이 가장 확실한 방법이며, 정부는 이를 기술과 제도로 지원하고, 그 수익을 국민과 공유하는 구조를 만들어야 한다”고 말했다.

◆ K-MELLODDY 산업단, '연합학습' 기반 신약 개발 첫걸음
한편, 이번 정책 제안의 실행을 이끌고 있는 K-MELLODDY 사업단은 국내 주요 병원, 제약사, 연구기관과 함께 ‘연합학습’ 기반 AI 신약개발 플랫폼 구축에 나서고 있다.
연합학습은 데이터 자체를 기관 외부로 이동시키지 않고, 각 기관이 개별적으로 AI 모델을 학습시킨 뒤 모델의 학습 결과(파라미터)만 공유함으로써 개인정보 유출 없이 협력 가능한 기술이다. 특히 병원 간 데이터 양의 불균형 문제를 기술적으로 해결할 수 있다는 점에서 주목받고 있다.
김 단장은 “병원마다 보유한 데이터 양이 다르기 때문에, 연합학습 없이 데이터를 직접 공유하면 규모가 큰 병원이 손해라고 느끼기 쉽다”며, “이런 불균형은 협업을 어렵게 만들 수 있지만, 연합학습은 모델 성능 향상을 통해 모두에게 이익을 줄 수 있다”고 말했다.
실제로, 해외에서는 미국 NIH(국립보건원)와 메이요클리닉 등 15개 병원이 공동으로 종양 세그멘테이션 AI 모델을 개발한 사례가 있다. 이처럼 다양한 인구군과 장비 특성이 반영된 데이터를 연합해 학습한 결과, 단일 병원보다 훨씬 높은 예측 정확도와 범용성을 지닌 모델이 완성됐다는 것이다.
김 단장은 “우리는 데이터를 거래하는 것이 아니라, 고성능 모델을 ‘공유’하는 구조를 만드는 것”이라며, “연합학습은 개인정보 보호와 AI 모델 최적화를 동시에 가능하게 하는 기술로, 신약개발 혁신의 핵심 열쇠가 될 것”이라고 강조했다.
- 이전 글| 산업/재계 | 한국제약바이오협회, HK이노엔서 '오픈하우스' 진행...정부기관 관계자 60여명 생산시설 견학2025.06.11
- 다음 글| 증권/금융 | 뉴지스탁, ‘2025 삼성금융 C랩 아웃사이드’ 본선 진출2025.06.11
회원로그인
회원가입